Setting up Apache Hive on your Machine
This is the third post of this series where we are setting up our machines to get started with learning big data. In the first post, we have installed and configured Hadoop on our Macbook and now we will install Apache Hive and use the same Hadoop cluster to save data in HDFS. Let's get started then.
Prerequisites
Installation
We will be installing Hive 1.2.2, so we need to update the brew formula (as we did for Hadoop in the previous article). Use brew edit hive to open the formula and edit it to have these values:
sha256 "763b246a1a1ceeb815493d1e5e1d71836b0c5b9be1c4cd9c8d685565113771d1"


Once you have updated the formula, install hive using brew install hive
Modify Hive Configurations
First things first, we need to edit the .bash_profile file. The hive installation directory is /usr/local/Cellar/hive/1.2.2, so update the .bash_profile file accordingly.

Setup for the Hive metastore - MySQL
We will configure a MySQL instance for the hive metastore. To do that, we need to setup mysql on our machine. Then we will setup JDBC connector to connect to the mysql instance. A prerequisite is to have wget installed on your machine. If it is not already installed, use brew install wget to install wget. Then follow these steps:
$ brew install mysql
$ mkdir ~/mysql/jars
$ cd ~/mysql/jars
$ wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.46.tar.gz
$ tar -zxvf mysql-connector-java-5.1.46.tar.gz
$ cd mysql-connector-java-5.1.46
$ sudo cp mysql-connector-java-5.1.46 /Library/Java/Extensions/
$ sudo chown kautukp:admin /Library/Java/Extensions/mysql-connector-java-5.1.46.jar
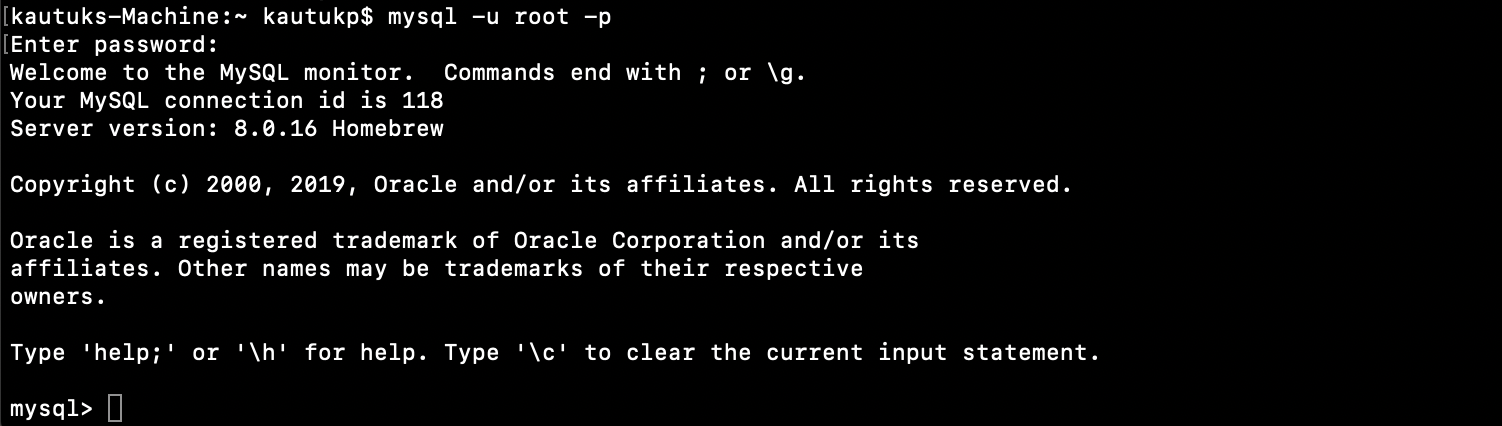
Start MySQL service
Start the MySQL service by running mysqld
As a test, try to connect to the instance by firing mysql -u root -p
Configure the metastore
We need to create a database which will be used for the metastore. We also need a user which will be used by Hive to connect to this DB. Follow these steps to do this:
> create database hive;
> use hive;
> create user 'kautukp'@'localhost';
> set password for 'kautukp'@'localhost' = 'your_password_here';
> grant all on hive.* to 'kautukp'@'localhost' ;
> flush privileges;
Update hive-site.xml
We need to configure hive to use the above mysql instance for the metastore. Go to the hive configuration directory. Go to the conf directory in HIVE_HOME. Create a new file with the name hive-site.xml. Add the following (after changing your folders, username, password etc.):
<configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>kautukp</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>enter_your_password</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/Users/kautukp/Documents/learning/hive/tmpData</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/Users/kautukp/Documents/learning/hive/tmpData</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/Users/kautukp/Documents/learning/hive/tmpData</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/apps/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
Starting Hive Services
To start and run hive, you need to start two services - metastore service and hiveserver (in that order, mind it).
$ nohup $HIVE_HOME/bin/hive --service metastore
$ nohup $HIVE_HOME/bin/hiveserver2
Using Hive CLI
Start the hive shell by running hive
Run some hql commands to test everything out.

Hive Query Timeout issue
In case you are facing timeout issues on your newly installed Hive setup, it is because you might not have set YARN properties yet. YARN is the resource manager for this Hadoop setup and it controls how many mappers and reducers get assigned to any Hive query fired. To fix this, go to your $HADOOP_CONF_DIR and edit yarn-site.xml. Add the following values in the file and restart your services (start-yarn.sh)
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>90.0</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>12288</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>6144</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>6</value>
</property>
And you are done! Quite straightforward, right?
In the next post, we will build on this progress and use this Hadoop and Hive instance to run Presto.

Casino Games Near Me | Mapyro
ReplyDeleteFind the best casinos near you, located in Denver, Colorado. Mapyro offers a 부산광역 출장안마 complete 전라북도 출장안마 inventory of gaming, entertainment, 강원도 출장마사지 and dining options 제주도 출장마사지 in the 대전광역 출장안마 state.