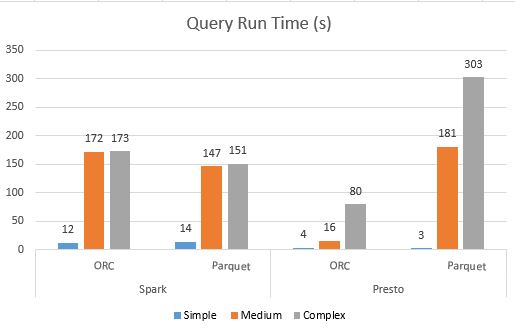
How Many Spark Executors Do I need?
After we have understood the key components of a Spark job in the last post , in this post I will explain how to come up with the configuration to control these components. Do note that these are just best practices and guidelines widely implemented in the industry, but these are not set in stone. You can always revisit these guidelines if your system behaviour needs slightly different configurations. Where to Start? In my experience, most people get stuck at this step because of the overwhelming number of settings and configs they can tweak. So, in this post I will try to give a simplified way to come up with these configurations. These come from Cloudera and are quite popular within the Big Data community. Then, I will walk you through a sample configuration which should help you understand the principles and see them in practice. Number of cores per executor: Most people actually stick to the two extremes while assigning number of cores for their executors. First ext...