UBER Data Architecture
In this post, I will try to cover the data architecture Uber has built to support their big data applications. This should be applicable for other ride hailing apps as well. There are multiple modules at play here so I will try to give a brief overview along with a detailed discussion on the data architecture.
An aeroplane view of the problem tells us that effectively we are trying to solve a demand vs. supply problem. All the Drivers active at any point of time constitute the supply while all the cab requesters (Riders) form the demand. What Uber tries to do is to have the best matching between demand and supply "at any point at any moment". I have highlighted the location and temporal conditions as they are critical for the success of what Uber tries to do. Let's get started to see how Uber comes around these challenges by creating a scalable data architecture.
Every Driver active on Uber keeps sending his location data to the server (e.g. every 5 seconds). This data keeps getting pumped to Kafka which keeps writing it to the DB layer. When a Rider requests a ride, Uber's match engine tries to find all the cabs close to the location of the rider and sends requests to all the Drivers available in that area. This includes all the cabs who are on the way to complete a trip in the vicinity. There are multiple problems Uber needs to solve here - map representation of the Driver and Rider, ETA calculation, Surge Pricing etc. I will try to cover these problems and how Uber is trying to solve them in another post in the future.
Data Architecture
A key requirement for any such service is the high availability and scalability needed for 100% uptime of the service. Uber manages that by using a lot of technologies which are loosely coupled and work asynchronously from each other. All the requests sent from the apps (Driver/ Rider) are routed through load balancers to Kafka topics. These load balancers are a mix of software and hardware load balancers. Once the messages are in Kafka, they are routed to multiple targets,
Databases: Any such service needs very fast reads and writes. Uber used to use MySQL for this earlier which they were trying to port to other DB stack. For such purposes, one can use Cassandra or DynamoDB as both of them are highly scalable NoSQL DB systems which can be tuned for very high reads and writes. This layer persists the location data of the Drivers as well as Riders along with other key metrics from the Matching service.
HDFS: Another target of the Kafka topics is the HDFS layer which can be leveraged in many use cases. Once the data is in HDFS, Uber does a lot of analytics on the data for a bunch of use cases. Uber uses both Spark and Hive for their high compute processing jobs while they use Presto quite heavily for adhoc SQL query capabilities on top of HDFS. By using Hive's HCatalog service for the metastore, the same data can be exposed via different services without actually making copies of data.
ELK: Most of the systems involved keep generating logs and analyzing these logs gives a lot of insights into any ongoing issue or performance metrics. These logs get moved to ElasticSearch where they can be analyzed using Logstash and Kibana.
 |
| Data Architecture |
Machine Learning models: Uber employs a lot of ML at different stages to predict user behaviour and optimize their processes. These models run by calling services to access features stored in different data layers. There are hundreds of ML models which predict a bunch of metrics while running in offline or online mode. Offline ML models are the ones where the models can run on HDFS via Spark/ Hive and store the results back (to both HDFS and DB Layer).
Uber also employs a lot of Online ML models to feed low latency predictions. Within Online, there are some Batch models which need features to be precomputed and stored so that they can be "looked up" when the app needs it (e.g. The average meal preparation time for a restaurant for last one month). In such cases, pre-computes happen in HDFS and the results get stored in Cassandra gets accessed at run time. There are cases where the feature generation needs to be done near real time. In such cases, Kafka directly writes into Cassandra and feature generation happens there itself and gets persisted to HDFS for future predictions (e.g. average meal preparation time for last hour).
This article was my attempt to think from an outsider's view and design Uber's data architecture. Lot of things might be different from what Uber have done but I hope this will give some idea to readers about how to approach such problems. I hope you enjoyed that, do share your feedback.
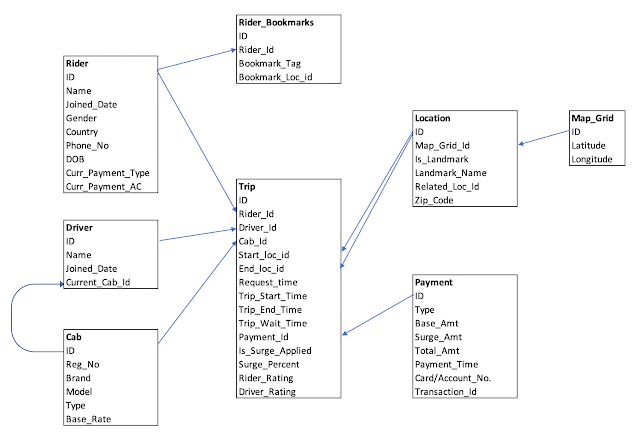
For Uber's data model, read Uber Data Model
References:
https://eng.uber.com
https://eng.uber.com/michelangelo/
https://eng.uber.com/schemaless-part-one/
https://eng.uber.com/uber-big-data-platform/
Uber also employs a lot of Online ML models to feed low latency predictions. Within Online, there are some Batch models which need features to be precomputed and stored so that they can be "looked up" when the app needs it (e.g. The average meal preparation time for a restaurant for last one month). In such cases, pre-computes happen in HDFS and the results get stored in Cassandra gets accessed at run time. There are cases where the feature generation needs to be done near real time. In such cases, Kafka directly writes into Cassandra and feature generation happens there itself and gets persisted to HDFS for future predictions (e.g. average meal preparation time for last hour).
This article was my attempt to think from an outsider's view and design Uber's data architecture. Lot of things might be different from what Uber have done but I hope this will give some idea to readers about how to approach such problems. I hope you enjoyed that, do share your feedback.
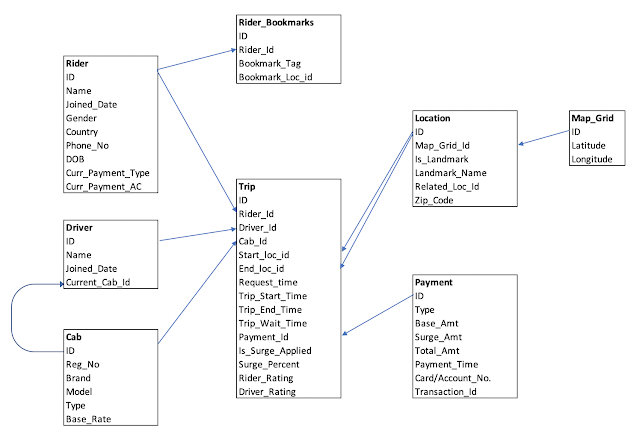
For Uber's data model, read Uber Data Model
References:
https://eng.uber.com
https://eng.uber.com/michelangelo/
https://eng.uber.com/schemaless-part-one/
https://eng.uber.com/uber-big-data-platform/
Comments
Post a Comment