Hive vs Spark vs Presto: SQL Performance Benchmarking
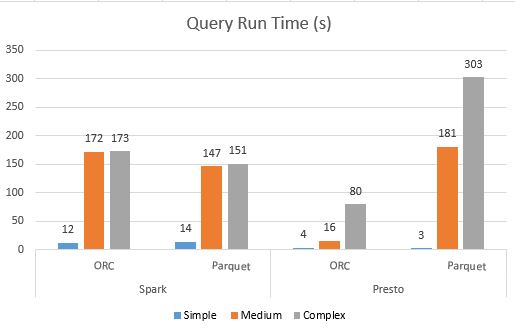
In my previous post, we went over the qualitative comparisons between Hive, Spark and Presto . In this post, we will do a more detailed analysis, by virtue of a series of performance benchmarking tests on these three query engines. Benchmarking Data Set For this benchmarking, we have two tables. Some of the key points of the setup are: - All the query engines are using the Hive metastore for table definitions as Presto and Spark both natively support Hive tables - All the tables are external Hive tables with data stored in S3 - All the tables are using Parquet and ORC as a storage format Tables : 1. product_sales: It has ~6 billion records 2. product_item: It has ~589k records Hardware Tests were done on the following EMR cluster configurations, EMR Version: 5.8 Spark: 2.2.0 Hive: 2.3.0 Presto: 0.170 Nodes: Master Node: 1x r4.16xlarge Task nodes: 8 x r4.8xlarge Query Types There are thre...



