Cracking Data Engineering Interviews
Of late, a lot of people have asked me for tips on how to crack Data Engineering interviews at FAANG (Facebook, Amazon, Apple, Netflix, Google) or similar companies. I have not worked at all of these companies so I can't share tips which will necessarily apply for all of them but I will share tips which can be generalized for most of the big companies.
First of all, the field of Data Engineering has expanded a lot in the last few years and has become one of the core functions of any big technology company. The obvious reason for this expansion is the amount of data being generated by devices and data-centric economy of the internet age. Each company is focussed on making the best use of data owned by them by making data driven decisions. If you compare this to the Data Engineering roles which used to exist a decade back, you will see a huge change. In the past, Data Engineering was invariably focussed on Databases and SQL. Even now, these two form some part of most Data Engineering stacks but things have grown a lot towards the NoSQL world. Another major change happening right about now is the push towards real time analytics via Streaming applications. Combine all these together and Data Engineering becomes a quite daunting field with ever changing stacks and ever moving goal posts. In this post, I will try to break it down into pieces which can be grouped together for preparations. These are based on hundreds of interviews I have taken and loops I have been part of over the years working as a Data Engineer. I will also try to add useful resources which can be used for your preparation.
Most of the big companies will try to evaluate a Data Engineer( mid-senior level) candidate for the following skills:
Coding
NoSQL Stack
Databases + SQL
ETL - Batch + Streaming
Data Architecture and Design
I will briefly describe each of these skillsets and how companies evaluate candidates for these skills.
Coding
Most technology companies will want to evaluate a candidate on the coding skills. Depending on the exact role/ org/ company, it might be an intense coding session or just a verbal interview to check the coding concepts. Most popular languages in the field are Python, Java and Scala. So, brush up your coding skills using online resources like Leetcode, HackerRank etc. You can also practice on online compilers like,
Python Resources:
NoSQL Stack
Most of the companies now have so much data that Hadoop and its assorted list of Apache toolset has become omnipresent. Though each company has its own technology stack, most are a combination of few popular ones. For storage, most places use HDFS (or some variant) because of the level of support for different technologies. For the processing part of the stack, Spark has become the most popular framework. A lot of places are still using Hive for legacy support. For the query engines, HiveQL is still very popular, even though a lot of people are moving to Presto/ SparkSQL etc. Though most big companies use the Apache version of these technologies, there are a lot of managed solutions in place as well. AWS has EMR which gives you a managed Hadoop cluster and services, DataBricks, HortonWorks etc. have similar offerings.
It is daunting to be a master of all these technologies. The key here is to understand what to use when and why. E.g. You might get asked about the strengths of Presto against Spark and when to use which one in real life scenarios. Refer to some of the posts below for more use cases, examples and exercises:
Setup Hadoop on your machine
Setup Hive on your machine
Setup Presto on your machine
Hive vs Spark vs Presto
Sample NoSQL Scenarios
Setup Hadoop on your machine
Setup Hive on your machine
Setup Presto on your machine
Hive vs Spark vs Presto
Sample NoSQL Scenarios
Databases + SQL
Even though there have been a lot of advancements in Data Engineering world, it is a fact that a lot of analysis happens over SQL. Which means, a good Data Engineer should know key fundamentals of databases (partitioning, indexes, High Availability, Disaster Recovery etc.). Also, you should be good in SQL. Most of these companies will have one interview to evaluate your SQL skills so make sure that you practice a lot.
Sample SQL Interview
SQL Practice Resources:
https://www.w3resource.com/mysql-exercises/
Sample SQL Interview
SQL Practice Resources:
https://www.w3resource.com/mysql-exercises/
ETL/ Data Pipelines
Playing with tons of data means that Data Engineers spend a lot of time building (and maintaining) Data Pipelines to move data around systems. A lot of people I have interviewed mistake this to just tools ("I know Talend/ Informatica/ <random tool here>"). That is not an entirely convincing way to learn about data pipelines. Engineers at big Tech companies are supposed to keep moving to better systems all the time. Which means that knowledge of specific tools become irrelevant very quickly. Rather, a better way is to understand different ways data can be moved around from/ to different types of systems. E.g. An AWS centric team might rely heavily on S3 as the storage layer and access this layer using AWS SDKs for Spark while just using Python to load data into Redshift from S3. Similarly, another team might be using Airflow to build and orchestrate their Data Pipelines to read/ write data into their HDFS layer.
The key here is to understand the generic approach for each type of systems. It is preferable to gain expertise of a few of these (e.g. Airflow, Oozie, Talend etc.).
Another big push that is transforming the field is the move towards real time analytics using Streams. Streaming brings in a whole new level of complexity as most of the times batch designs will not work for streams. You will need to understand how Lambda architectures work to support both Streams and Batches for huge volumes of data. Also, Streaming apps need another specialized set of databases designed for fast reads (e.g. Cassandra, DynamoDB etc.). These databases allow dimension lookups at mind-numbing speeds to allow for the streams to not get delayed because of these lookups.
Data Architecture
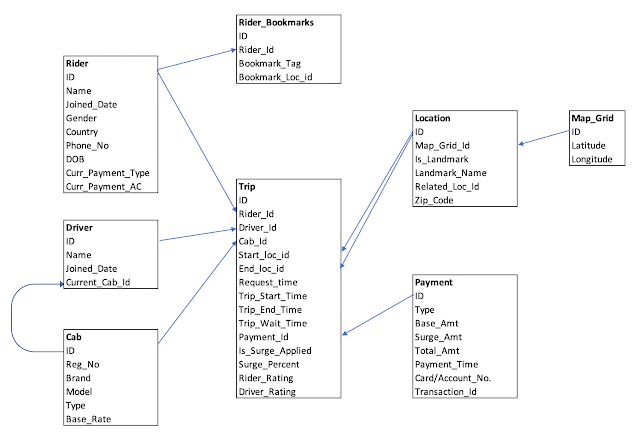
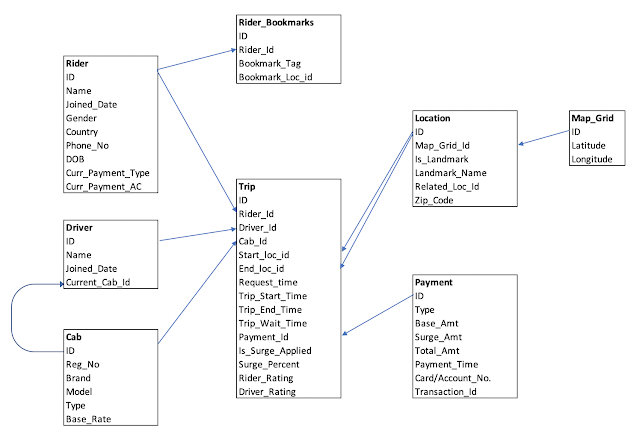
This section acts as the glue for all the things above. You need to know what fits where and how. Most companies will have this round for experienced Data Engineers to evaluate the candidate's understanding of system design. Some companies will give you an open ended problem/ App and ask you to design the Data Platform for the situation (e.g. Design the data platform for Twitter/ Uber/ Youtube etc.). Sometimes, this might go in the old-school direction of Star/ Snowflake modelling for a data warehouse. This may cover various aspects like file formats (ORC/ Parquet/ Avro etc.), partitioning schemes, columnar vs rowstore storage, performance benchmarking processes etc.
Sample Architecture
Sample Architecture
Resources:
Plumbers of Data Science
Uber's blog:
AWS blog

Thank you so much for this nice information. Hope so many people will get aware of this and useful as well.
ReplyDeleteIndium Software
Cracking Data Engineering Interviews >>>>> Download Now
Delete>>>>> Download Full
Cracking Data Engineering Interviews >>>>> Download LINK
>>>>> Download Now
Cracking Data Engineering Interviews >>>>> Download Full
>>>>> Download LINK 84
Very Nice, Thanks for sharing such an informative Article, It was great reading this article. I would like to know more about it
ReplyDeletedata engineering course
Those who are looking for a data engineering solution in the UK must connect with the team of iTelenet. We have a team of experts who offer the right kind of services to deliver data engineering services.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThank you for sharing valuable content.
ReplyDeleteData Engineering Training